Ikony bez kompromisů

Ikony bez kompromisů
I přes svou malou velikost představují ikony na webu zajímavý problém. Jeden přístup střídá další –…








V našem Search týmu se, jak už jméno napovídá, věnujeme především vyhledávání na Heurece. Asi před rokem jsme přemýšleli, jak našim uživatelům ještě více zpříjemnit vyhledávání. Co kdybychom jim rovnou dokázali zobrazit konkrétní kategorii, produkt nebo e-shop a ne jen rozcestník? A navíc předvyplnit filtry? Podle našich uživatelských testů jsou pak spokojenější a každý ušetřený klik ocení. V tomto článku vám tedy zjednodušeně popíšu, jak přistupujeme k pochopení vyhledávaného dotazu (tzv. “Query Understanding”) na české a slovenské Heurece.
Podívejme se tedy nejprve na to, jak funguje základní vyhledávání na Heurece. Zjednodušeně napsáno, uživatelé na Heurece vyhledávají Produkty, například iPhone 12 Pro. Všechny ostatní prvky jako Kategorie (Mobilní telefony), Výrobci/Značky (Apple) nebo E-shopy (vymysleny-obchod.cz) slouží, z hlediska vyhledávání, hlavně jako kontext pro zobrazení relevantnějších Produktů ve výsledcích… Teď jsem si sice trochu hodně zapřeháněl, ale mnohem podrobnější informace obsahuje už článek kolegy Vládi.
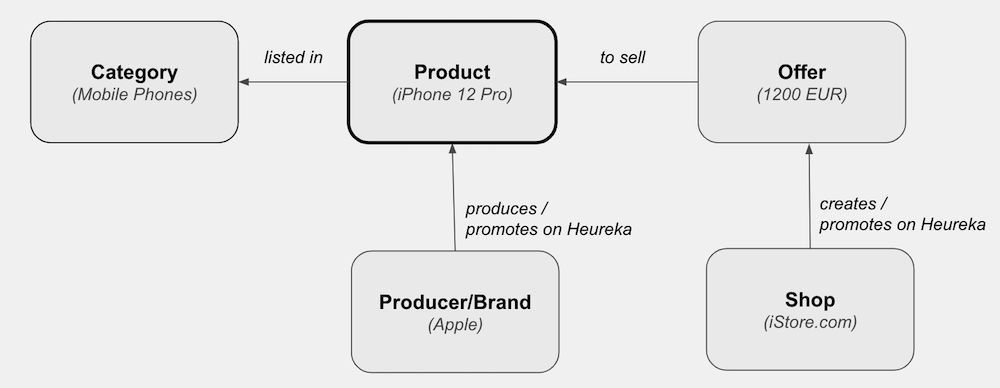
Jak vypadá typické vyhledávání na Heurece?
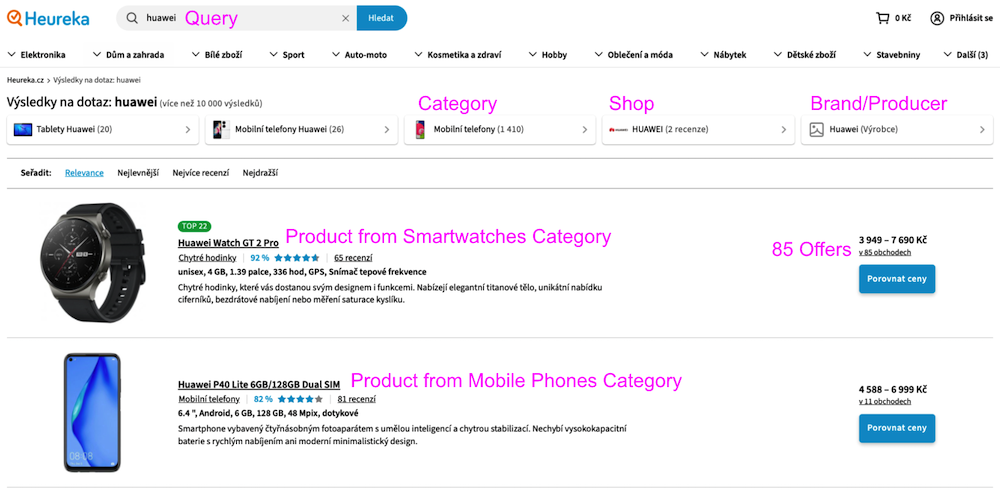
Pokud jsme si ale dostatečně jistí, že zadaná Query (nebo drtivá většina Produktů vyhledaných dle této Query) patří do jedné konkrétní Kategorie, rovnou do ní uživatele přesměrujeme. Čímž mu mimo jiné umožníme využít Filtry (barva, výrobce, cena, energetická třída, atp.) nebo strom kategorií (Elektronika – Mobilní telefony – Pro seniory) a tedy lépe specifikovat zobrazené Produkty. Win-win-win situace. Uživatel je spokojenější (máme změřeno), tedy zůstává na Heurece déle, prohlédne si více Produktů a zvyšuje se šance, že některý z nich i koupí. Profituje uživatel, Heureka i e‑shop. Prostě velká šťastná e‑commerce rodinka.
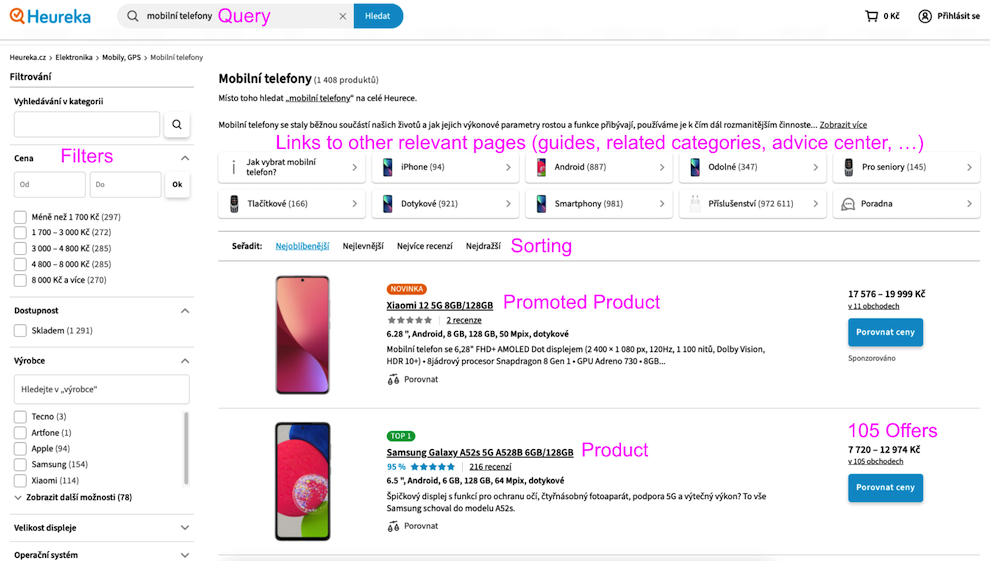
Obdobně můžeme rozhodnout, že daná Query s vysokou pravděpodobností (nejlépe hraničící s jistotou) odkazuje na konkrétní Značku nebo E-shop. Postup pak zůstává stejný, opět dojde k přesměrování uživatele na profil dané Značky či E-shopu.
Původní způsob přesměrování byl založen primárně na tzv. „přesné shodě“ (Exact Match). Pokud uživatel zadal do vyhledávacího pole naprosto přesně název Kategorie, Značky nebo E-shopu, bez chyb a překlepů, byl přesměrován. Byl to neprůstřelný způsob – přesměrování byla sice naprosto správná a očekávaná, ale bylo jich málo.
Proto jsme rozšířili možnost přesměrování o ručně definovaná pravidla. Nicméně ta nakonec sloužila spíše k pokrytí častých překlepů (např. setobox – Set-Top box) protože detekce, plnění a údržba takovýchto pravidel byla časově náročná. A nudná.
Proto jsme se začali věnovat „porozumění“ Query (Query Understanding):
Ukažme si na příkladu pro Query zadanou uživatelem: „Levný dotykový Samsung s NFC a Dual SIM“
V ideálním případě tedy z vyhledávané Query nezbyl žádný text a byla přeměněna na konkrétní Kategorii s aplikovanými Filtry.
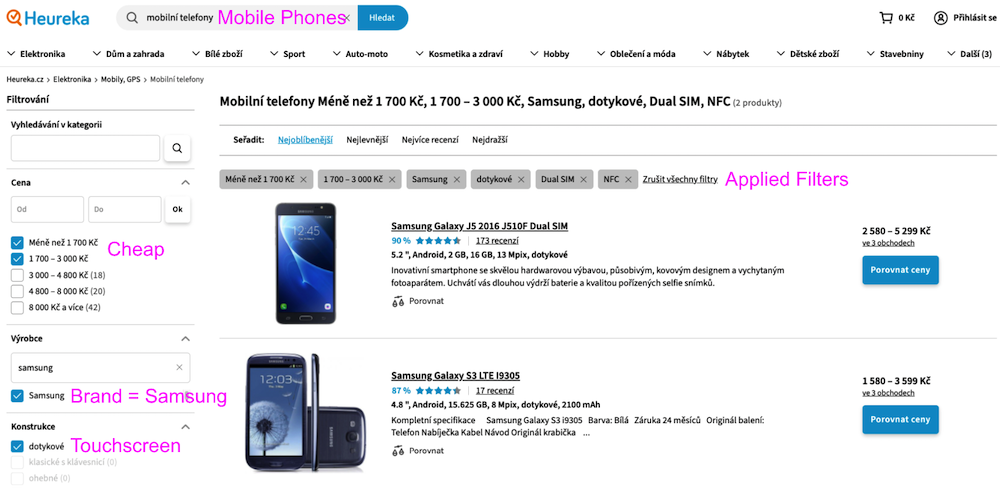
Rozpoznání Kategorie = získání (dalšího) kontextu = zpřesnění detekce (nejen) Filtrů. A Filtry jsou celkem 😊 důležité, představme si, že bychom předchozí cvičnou Query („Levný dotykový Samsung s NFC a Dual SIM“) detekovali jen jako Kategorii Mobilní telefony a s Filtry se už neobtěžovali… Na prvních místech bychom uživateli vypsali drahé iPhony, což není úplně jím očekávaný výsledek.
Ve zkratce řečeno – bez přesné (a dostatečně úplné) detekce Kategorií nelze příliš pokročit. Výhodou je, že strom Kategorií není příliš obsáhlý (máme jich tři tisíce), moc se nemění (desítky změn měsíčně) a je výtečně pokrytý SEO (synonyma, klíčová slova, atp.). Taktéž máme k dispozici miliony záznamů o dřívějších vyhledáváních… Dohromady slibná výchozí pozice pro trénování modelu strojového učení (ML modelu).
Pro účely tohoto článku berme ML model jako zázračnou černou skříňku. Jednou se k jeho vývoji vrátíme (slibem nezarmoutíš) v dalším článku o Vyhledávání na Heurece. Důležité teď je, že do této skříňky vložíme Query zadanou uživatelem a ona nám vrátí, do které Kategorie patří (a s jakou jistotou).
Filtry lze rozdělit do dvou skupin:
Podívali jsme se do statistik a zjistili, že obecné filtry jsou násobně používanější než unikátní – a zároveň mají přesah do mnohem více Kategorií. Proto jsme se rozhodli, že pro začátek se zaměříme na obecnou barvu, cenu a výrobce, vyhodnotíme je a unikátní Filtry prozatím necháme uležet. Za málo peněz hodně detekcí.
Značky, Produkty ani E-shopy nejsou (obecně) závislé na kontextu nalezené Kategorie. Mohou existovat samy o sobě, jako např. stránka recenzí E‑shopu nebo Produktový detail.
Přemýšleli jsme, zda máme vytvořit další strojový model, který by byl schopen rozpoznat například Produkty. Proto jsme si nejprve porovnali, jaký je vlastně mezi Kategoriemi a Produkty rozdíl:
Kategorie | Produkty | |
Počet | cca. 3000 | cca. 30 000 000 |
Podobnost názvů | malá, např. Mobilní telefony vs. Knihy | velká ve shlucích: iPhone 8, 9, 10, 11, 12, mini, PRO, 64 GB, 128 GB, … |
Počet změn | jednotky denně | stovky za sekundu |
Možné způsoby detekce | Název, synonymum, klíčová slova, výčet produktů, popis, existující filtry, … | Název, popis |
Z porovnání vidíme, že v existujícím modelu bereme v potaz Kategorie, kterých není mnoho. Jsou od sebe rozlišitelné jen dle názvu (a případně synonym) a prakticky se nemění. I tak je náš ML model schopen s vysokou přesností i úplností detekovat zhruba 1000 z nich. To nám nevadí, ostatní už nejsou tolik navštěvované – aneb pravidlo 90/10.
Proto jsme neměli úplně optimistické představy, jak bychom dopadli s kvalitou modelu u Produktů (nemáme neomezený rozpočet a zdroje, zatím 😀). Je mimochodem potřeba zmínit, že detekujeme Kategorii či Produkt v reálném čase jen za pomoci Query (většinou o max. pěti slovech). Což je rozdíl například oproti párování produktů, které probíhá dávkově a má k dispozici další metadata (obrázky, popisky, cenu, výrobce, prodejce, atd.)
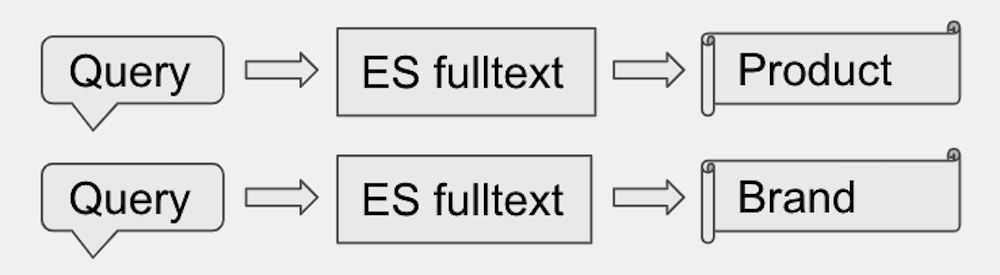
A je vlastně vůbec ML model potřeba? Vždyť u Produktů máme k dispozici (zjednodušeně) jen název a popis. Takže můžeme využít stávající a ověřený způsob pomocí real-time vyhledávání v Elasticu. A tady opět připomínám Vláďův článek.
Dobře, nyní jsme schopni detekovat Kategorii, Značku, E‑shop, Produkt a obecné Filtry. Jenže každou z těchto entit několika způsoby (přesná shoda, Elasticsearch query, ML model, číselník hodnot a ještě další, které jsem pro jednoduchost vynechal), a to vše navíc v několika kontextech:
Spousta otázek.
Walmart sice řeší trochu jinou oblast (zařazování Produktů do Kategorie), ale narazil na obdobné otázky. Nicméně jejich řešení bylo rámcově aplikovatelné na náš problém. Skládá se ze tří základních přístupů – Strojového učení, odborníky psaných analytických pravidel a ověřování kvality davem (CrowdSourcing). Při využití jejich předností a potlačení nevýhod:
Iterovat, iterovat, iterovat a z iterací se učit a zdokonalovat. Nově zadaná manuální pravidla i negativní zpětná vazba od uživatelů generují nové vstupy pro další trénování ML modelu (a ML model naopak generuje nové vstupy pro opravná pravidla 😅). Každá další iterace ale musí zachovat požadovanou přesnost (95 %) a zvyšovat úplnost.
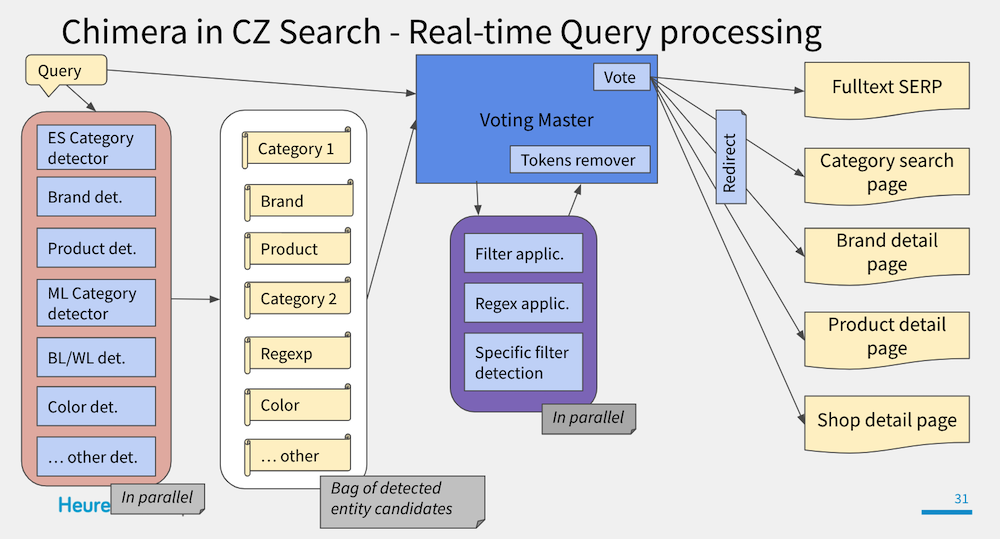
Mějme několik detektorů Kategorie a jejich změřenou přesnost:
Voting Master má rozhodnout, který z nich je správný:
Počítání celkového skóre
Mimochodem, přesný vzorec stále vylepšujeme na základě zpětné vazby našich uživatelů. Pokud tedy narazíte na nerelevantní výsledky vyhledávání, budeme rádi, když nám o nich dáte vědět.
Dnes tedy máme většinu přesměrovávacích pravidel vymyšlenou, z velké části implementovanou a leckteré části i nasazené. Alespoň v Česku a na Slovensku. Pomalu se tak dostáváme k učení se cizích jazyků v rámci všech zemí v Heureka Group.
Snad vám tedy tento článek přiblížil, co a jakým způsobem lze zjistit z těch několika málo slov, která zadáváte do vyhledávacího pole na Heurece.
Marek je součástí týmu Staff Engineerů, který se zaměřuje na hledání nejlepších nástrojů a způsobů, jak propojit různé části systému, aby vše probíhalo hladce, i když se věci zkomplikují.
Seznam kategorií


 Dej nám follow
Dej nám follow
 Dej nám follow
Dej nám follow