Ikony bez kompromisů

Ikony bez kompromisů
I přes svou malou velikost představují ikony na webu zajímavý problém. Jeden přístup střídá další –…








Vyhledávání na Heurece se může zdát stejné jako vyhledávání na e‑shopu. Je to velmi podobné, ale má to svá specifika. Vyhledáváme nejen v našem katalogu produktů, v kategoriích, značkách, ale i v „nabídkách“. Dá se tomu rozumět tak, že „produkt“ je pro nás jedna produktová karta, která může obsahovat jednu a více „nabídek“ („iPhone SE“ nabízí k prodeji desítky různých e‑shopů).
V tomto článku vám zkusím v krátkosti uvést, kde bereme data, jak často se aktualizují, jaká různá APIs máme a co a jak máme nakonfigurované. Cílem je vám ukázat, co je technicky potřeba pro výběr vašeho vysněného produktu. I když jsme již mezinárodní firma, stále máme dost věcí oddělených. Popíšu vám pouze vyhledávání na Heureka.CZ a SK a také naše české a slovenské “satelity” (kauf.sk, srovnanicen.cz,..).
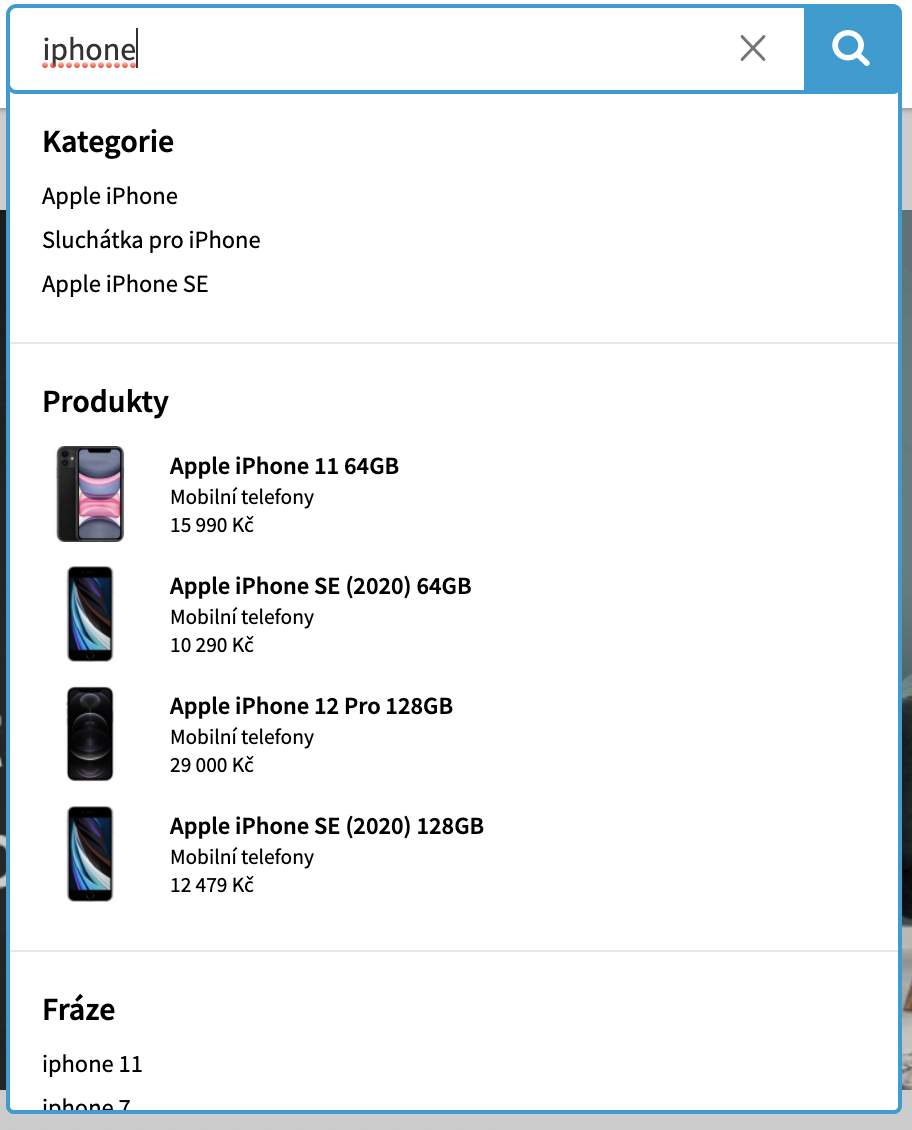
Vyhledávání pro nás znamená zejména sadu nástrojů pro předávání uživateli relevantní odpovědi na daný dotaz ve “fulltextu” a v “našeptávači”, ale pro náš tým je to i předávání dat pro výpisy produktů v kategorii, u značek apod. Pro nás na backendu totiž filtrovat a vyhledávat produkty v kategorii nebo fulltextu je rozdílné pouze v tom, že v kategorii je vyhledáváno s filtrem na danou kategorii.
Pro uživatele by to nejlépe mělo fungovat tak, že dostane na vyhledávací dotaz “červený iPhone” stejné produkty ve fulltextu, jako kdyby si vyfiltroval červenou barvu a značku Apple v kategorii Mobilní telefony. U určitých “klientů” vracíme více typů dat, jak už jsem poznamenal v úvodu - jsou to produkty, “nabídky”, kategorie, značky, e-shopy apod.
Pro vyhledávání jsme nejvíce závislí na našem ElasticSearch clusteru (dále jen “ES”), který máme společný pro oba jazyky a všechny typy dat. Data jsou rozdělena do indexů dle typu. Indexujeme je z různých zdrojů ostatních vývojových týmů, zejména z naší společné MySQL databáze a APIs, které se starají o správu Katalogu, Recenzí apod.
Vše nám běží v Pythonu v Docker images a na našem (on premise) Kubernetes clusteru. Vše je rozděleno do mikroslužeb tak, aby se jednotlivé operace co nejlépe škálovaly. Deploy provádíme kompletně přes GitLab pipelines, které nám umožňují jednoduše na pár kliknutí dostat změny do produkce.
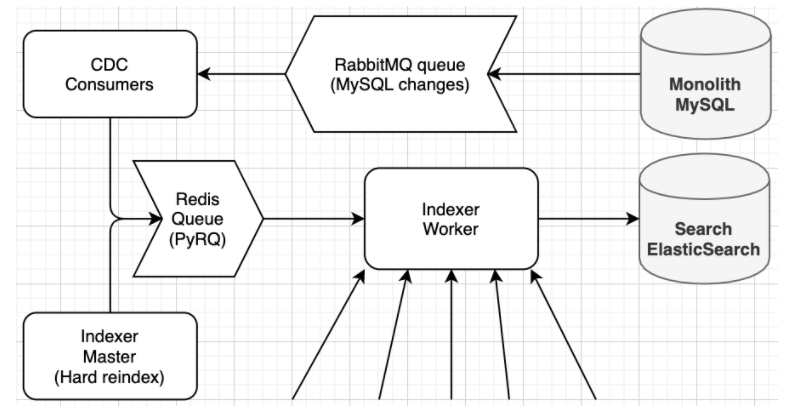 Jako Heureka máme tzv. Monolith MySQL, ve které je velké množství dat. U této databáze je aplikace Maxwell (CDC), která čte bin-log změn v databázi a odesílá tyto změny do RabbitMQ, kde je “bind”(přiřazení) různých tabulek do RabbitMQ front.
Jako Heureka máme tzv. Monolith MySQL, ve které je velké množství dat. U této databáze je aplikace Maxwell (CDC), která čte bin-log změn v databázi a odesílá tyto změny do RabbitMQ, kde je “bind”(přiřazení) různých tabulek do RabbitMQ front.
U nás pak provádíme kontinuální změny takto:
Pokud e-shop upraví produkt, změna se projeví během pár minut na vyhledávání Heureka.cz. Jednou týdně (a v případě naší potřeby) se vyvolává hard reindex, který vytvoří index nový a po zaindexování veškerých dat se prohodí čtecí a zapisovací alias. Celý proces je řádově složitější, protože obsahuje malé desítky dalších mikroslužeb. Toto je ta hlavní část, která změny v ES provádí.
Aktuálně máme dvě verze Search API. První, která je již deprecated a druhá, kterou již používá naprostá většina klientů (frontend služby,..). Verze 1 používá pro výpis návratových hodnot Monolith MySQL (v ES dohledává pouze IDs). Verze 2 používá data source dokumentů z ES a je napsána kvůli výkonu v Async. Pythonu. Díky těmto architektonickým změnám je druhá verze asi 5x rychlejší.
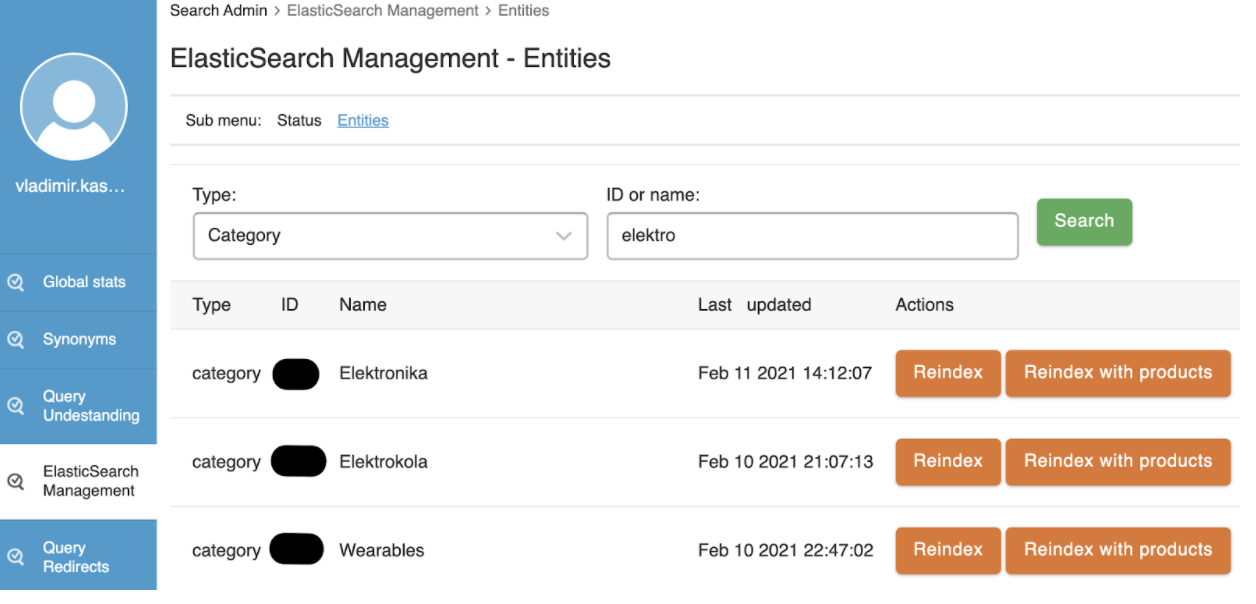
Máme k dispozici administraci, která nám pomáhá spravovat data v ES (máme možnost reindexovat nesprávné hodnoty), spravovat synonyma (“vozidlo”->”auto”) nebo přesměrování.
Díky tomu můžeme mnohem rychleji reagovat na problémy a změny, což je jednodušší, než složité reindexování všech dat.
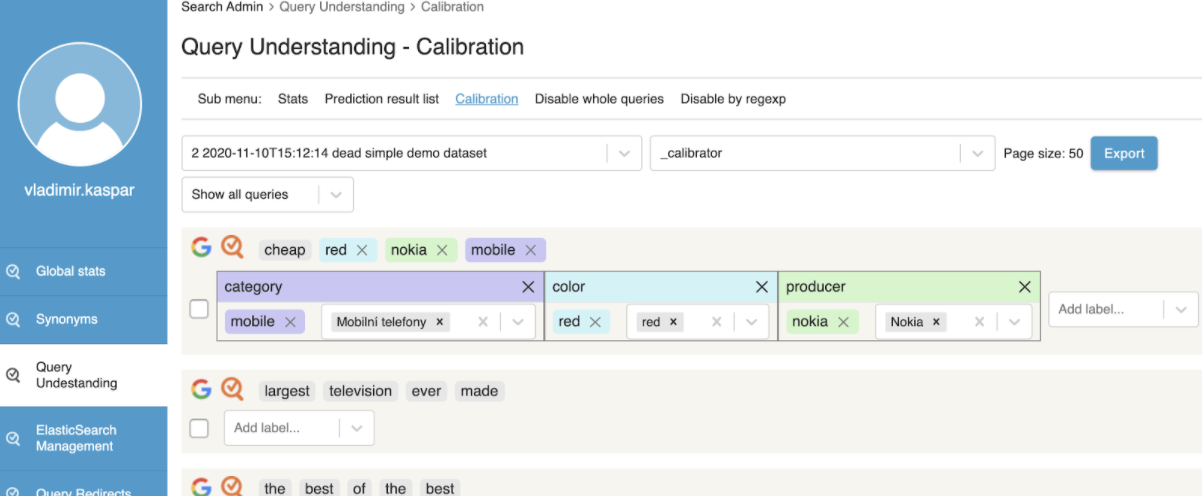
Aktuálně pracujeme na rozvoji našeho machine learning modelu, který nám dle zadaného dotazu určuje konkrétní kategorii, značku, výrobce a další atributy. Analýzy a učení modelu provádíme ve Sparku v Databricks (v Azure). Data získáváme z anonymizovaného seznamu zadaných queries z Google Analytics a z Crowd Evaluation v naší administraci. Tímto projektem chceme uživatelům nabídnout lepší výsledky ve fulltextu, případně je přesměrovat do kategorie s vybraným filtrem, jak jsem popsal výše s příkladem červeného iPhonu.
Celý cluster máme v našem Kubernetes a používáme všechny 4 role odděleně a to v počtu:
Veškeré data jsou 1x denně zálohovaná do našeho S3 storage.
Z celé řady statistik, které máme, víme, že nejvytíženějším datovým typem jsou produkty. Proto pro ně máme polovinu ES clusteru vyčleněnou pomocí ES attributes. Pro představu uvádím počty shardů, replik a počtu dokumentů:
Doufám, že po přečtení tohoto článku máte představu, co vše je potřeba, abyste si mohli vyhledat a vybrat produkt k nákupu. Pokud máte jakoukoliv otázku nebo vás zajímá nějaká další oblast našeho vývoje, napište mi na vladimir.kaspar@heureka.cz.
Na úplný závěr bych chtěl poděkovat lidem v našem týmu, kteří proaktivně řeší jakékoliv požadavky a vše kolem vývoje našich služeb. Uživatelé naší Heureky se mohou těšit v budoucích měsících například na nový našeptávač, který přinese celou řadu inovací.
Vývojář, který se zasekl v Heurece na téměř 7 let. Těší se z technologií a super spolupráce v týmu. V soukromí výletník a dobrovolný hasič z maloměsta.
Seznam kategorií


 Dej nám follow
Dej nám follow
 Dej nám follow
Dej nám follow