Některé z našich subdomén fungují dobře. O těch tu však řeč nebude. Tento článek je totiž zaměřený na chirurgické vyřezávání cca 1000 subdomén, které generovaly miliony zbytečných duplicit. Operace trvala přes půl roku a její příprava téměř rok. Co přesně jsme dělali a jak se to povedlo?
Úvod
Tento článek je druhý díl ze série textů „Satan, SEO a Subdomény. „V předchozí části s podtitulem“Chaos přichází plíživě“, jsme se zabývali obecnými otázkami a koncepty, limity technologií a kyberprostoru a také stručnou historií Heureky. Teorie bylo dost, nyní se vrhneme do enterprise-level SEO praxe.
V rychlosti si pojďme zopakovat přehled čtyř hlavních typů subdomén Heureky:
- Základní, systémové a mobilní subdomény (
www, m, blog, info) ~20 subdomén. - Kategorické subdomény (
notebooky, mobilni-telefony, elektronika) ~2500 subdomén. - Brandové subdomény (
sony, nikon, apple) ~60.000 subdomén. - Parametrické subdomény (
herni-notebook, android-telefony, xbox-360) ~1000 subdomén.
V tomto textu se budeme detailně věnovat poslednímu bodu, tedy tisícovce parametrických subdomén, které začaly vznikat v roce 2010.
Hypotéza parazitických nádorů
Najít chybné vzorce chování a slabé články v systému s 65.000 subdoménami a sextiliony funkčních URL je docela oříšek. Představte si hromadu 650 kg nevyloupaných vlašských ořechů. Z toho necelých 10 kg uvnitř obsahuje shnilé a plesnivé jádro prolezlé červy. Jak najdete a oddělíte to, co je zkažené? Jak najdete subdomény nakažené kybernetickou rakovinou?
My jsme začali všechno přebírat manuálně. V době automatizace a spousty vymakaných nástrojů to zní docela děsivě. Neměli jsme ovšem na výběr. Žádný nástroj si s webem nezvládl rozumně poradit. „Zábavná“ nevýhoda skutečných potřeb entreprise-level webů je, že vůbec nespadají do tabulek nástrojů (primárně crawlerů), které nabízí „custom enterprise-level tarify“.
Zapojili jsme mozky, začali zpracovávat web po menších segmentech a dali se do ruční identifikace vzorců.
Postupně jsme ve stromu kategorií začali narážet na zvláštní sekce nejnižších úrovní, které vykazovaly nezvyklé chování. Ve skutečnosti se totiž vůbec nechovaly jako nižší úrovně stromu. Datově nedávaly smysl, měly naprosto tragický organický výkon a generovaly nesmyslně velký objem URL. Interně se označovaly jako „parametrické kategorie“ či také „parametrické sekce“. A po delším zkoumání strukturálně spíše připomínaly rozsáhlé nádory, které z kategorií prorostly ven.
Karta parametrického pacienta
Co přesně je „parametrická kategorie“? Je to pseudo-kategorie, která reprezentuje důležitou klíčovou frázi a jejím základem je již existují kategorie. Nejjednodušší to bude vysvětlit na konkrétním příkladu.
Kategorie. Když se podíváte do kategorie Mobilní telefony, tak v horní části uvidíte blok odkazů (viz též obrázek níže). Ty vedou do pseudo-kategorií, které označujeme jako parametrické sekce. Například Apple iPhone.
Parametrická. Vzniká na základě produktových parametrů. Parametrická sekce Apple iPhone je kombinací kategorie Mobilní telefony a parametru (filtru) výrobce Apple.
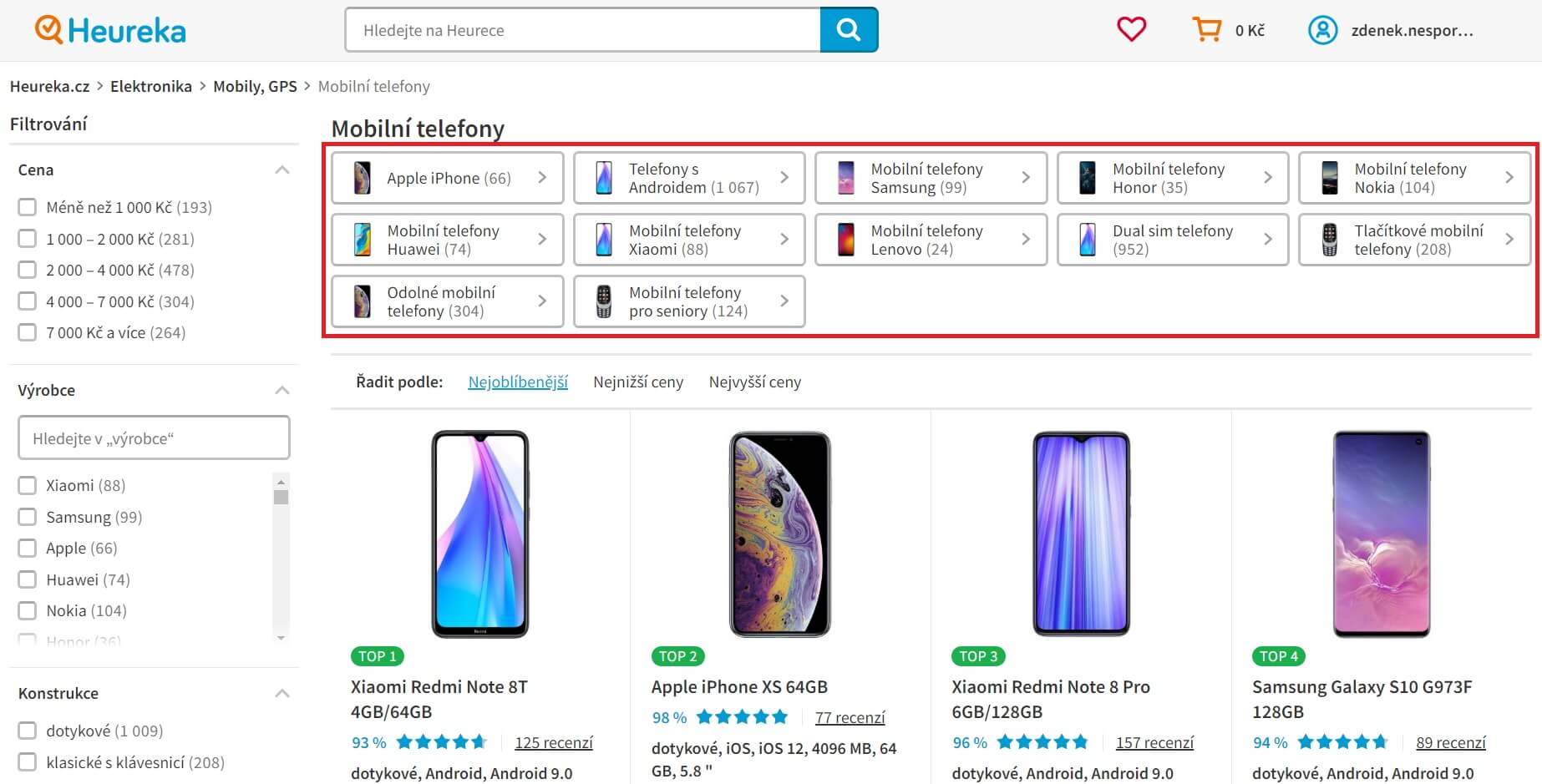
Anamnéza
Původní systém parametrických sekcí fungoval následovně. Potřebujeme uživateli nabídnout populární produkty „Apple iPhone“. Pro ty existuje cílová stránka, kterou tvoří kombinace kategorie Mobilní telefony a v ní zakliknutého filtru Výrobce -> Apple. Výsledkem je parametrická URL https://mobilni-telefony.heureka.cz/f:1666:101069/.
Za normálních okolností by tato URL a daná cílová stránka byly plně dostačující. V roce 2010 ovšem panovalo přesvědčení, že subdomény přináší „lepší SEO“, ať už to znamená cokoliv. A důležitá zřejmě byla kvantita, která měla převážit nad kvalitou.
Parametrickou URL https://mobilni-telefony.heureka.cz/f:1666:101069/ jsme proto vzali a v administračním systému ji použili jako základ pro subdoménu https://iphone.heureka.cz. Na pozadí došlo k tomu, že všechny filtry relevantní pro produkty s parametrem f:1666:101069 byly automaticky zkopírovány na novou subdoménu, kde vytvořily duplicitní systém parametrických URL.
Mobilní telefony iPhone pak byly dostupné na URL https://mobilni-telefony.heureka.cz/f:1666:101069/ i https://iphone.heureka.cz v identické podobě.
Rentgen
Pro lepší pochopení to zkusíme ještě popsat na obrázku. Obrázek Mandelbrotovy množiny reprezentuje kategorii. Červený rámeček představuje nějakou část kategorie, ze které by mělo smysl vytvořit parametrickou sekci.

Všechno v červeném rámečku jsme vzali a zkopírovali na nižší úroveň v podobě pseudo-kategorie. Obě fungovaly paralelně vedle sebe jako duplicity se stejnými základními vlastnostmi. A stejným potenciálem vygenerovat obří množství URL díky nevhodně ošetřené parametrické filtraci. To je i důvod proč jsme zvolili obrázek fraktálu, byť se jedná spíše o účelovou vizuálně-literární paralelu nikoliv o přesný příměr.

V této chvíli je už celkem jasné, jaký je náš hlavní cíl. Chceme, aby existovala pouze hlavní kategorie. Subdomény s replikovaných obsahem bude nutné přesměrovat. A parametrické sekce již budou vznikat pouze zvýrazněním konkrétního obsahu přímo v kategorii. Nebudou vznikat žádné nové subdoménové pseudo-sekce, ale parametrické sekce budou fungovat jako rychlé „zkratky“ k předvoleným filtrům. Žádná velká věda.
Tomografie zmrzlinové kategorie
Celý problém duplikace a následné optimalizace vám nyní představíme prostřednictvím detailního rozboru sítě webu. Zvolili jsme si pro tento účel kategorii zmrzliny.heureka.cz, protože patří mezi ty menší a ještě relativně jednoduše vizualizovatelné. Poslední krok vizualizace dokonce vzdáleně připomíná kopeček zmrzliny v kornoutu, což je pěkný bonus.
1. První obrázek reprezentuje kompletní dataset kategorie a tří parametrických sekcí. Černou barvou je označena kategorie. Modrá, červená a zelená označují tři parametrické sekce. Šedá barva pak představuje nadbytečné URL, které vznikají nedůsledným nastavením pravidel pro tvorbu interních linků. Jedná se o jistou formu spider trap, se kterou nyní nebudeme pracovat. Tyto nadbytečné URL proto do dalšího kroku odfiltrujeme.
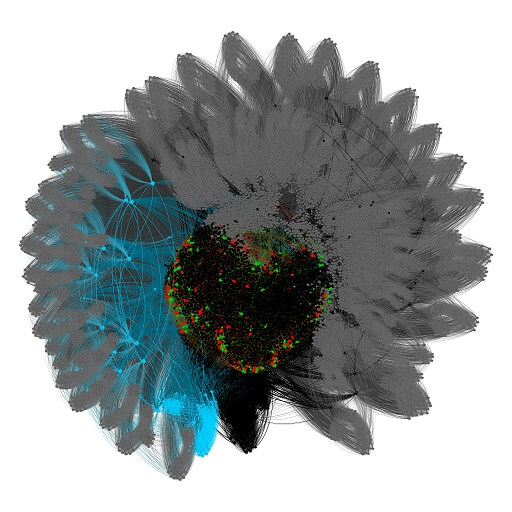
2. Druhý obrázek představuje očištěnou kategorii, její parametrické sekce a produkty. Ještě je nutné provést další filtraci dat a zbavit se produktových URL.

3. Na třetím obrázku zbývá pouze jádro kategorie a parametrických sekcí. Nyní můžeme v dalším kroku vizualizovat a identifikovat duplicity.

4. Zdrojové URL parametrických kategorií jsou zobrazeny jako světlejší odstín dané barvy. V případě modrých uzlů, které tvoří trošku komplexnější strukturu, si můžete všimnout podobností mezi modrým a světle modrým clusterem. Po izolaci jádra a jasné identifikaci duplicity známe vzorec, na základě kterého je možné začít připravovat a nasazovat 301 redirecty duplicit.

5. Po redirectování zbyde jen čisté jádro kategorie.

6. Na jádro kategorie nyní můžeme opět navázat produkty. Výsledkem je kategorie zmrzlin bez duplicit.

Laboratorní výsledky
Obrázky webového grafu jsou sice poutavé na pohled, ale nezkušenému oku mnoho neřeknou. Slouží primárně pro vizuální reprezentaci dat a zjednodušují hledání nestandardních vzorců. Podstatným faktem teorie grafů je, že se jedná o (diskrétní) matematické modely. Klíčovým výstupem tedy není vizuální reprezentace grafu, ale výpočty prováděné pomocí specializovaných algoritmů.
Metriky, které nás zajímají jsou například průměrná délka cesty na webu, interní ranking jednotlivých URL, „propustnost“ toku ranků, modularita sítě, průměr sítě a další.
Rozbor tkáně v.1
Na prvním obrázku vidíte změnu původní sítě (vlevo) a sítě po odstranění duplicit v kategorii (vpravo), které generovaly parametrické subdomény.

Mírně klesla průměrná délka cesty v kategorii. To znamená, že uživatel musí udělat v průměru o 0,01 kliknutí méně, aby se dostal ke stránce, která ho zajímá. Pro robota vyhledávače to znamená, že bude nyní procházet web procházet o něco málo efektivněji. Jistě, setina kliknutí se zdá být zanedbatelná, ale v součtu za celý gigantický web to není až tak málo. Snížení délky průměrné cesty je vždy pozitivním pokrokem.
Také klesla modularita sítě o 0,035. Modularita v zásadě vyjadřuje komplexitu sítě – sílu a hustotu propojení mezi jednotlivými clustery. My jsme nějaké clustery uzlů a propojení odebrali a modularitu tím pádem snížili. V našem případě se jedná o pozitivní efekt, ale neznamená to, že snižování modularity by mělo být nějakým důležitým úkonem. Naopak. Tuto metriku je spíše nutné posilovat a budováním efektivní sítě.
Poslední uváděná je metrika průměru sítě, která klesla o 1. Opět nelze univerzálně říct, že nižší hodnota je lepší, protože je závislá na více faktorech. V našem případě je pokles pozitivní, ale snižování či zvyšování průměru sítě není cílem optimalizace. Jde spíše o sekundární ukazatel.
Rozbor tkáně v.2
Na druhém obrázku pak vidíme srovnání výchozího stavu se spider trap (vlevo) a opět stavu po zrušení parametrických duplicit (vpravo). Jak již bylo dříve zmíněno, šedé uzly na okraji grafu jsou něco, co se označuje jako „spider trap“.
Odstranění příčiny a důsledku tohoto problému nás teprve čeká, ale jak můžete vidět spojený efekt všech změn, pak již bude opravdu zásadní. Dojde ke snížení snížení průměrné délky cesty o 1,944, což pro nás bude obrovský pokrok! Ale to už je téma do jiného článku a jiné série.

Snad jsme vám tímto alespoň trochu umožnili pochopit, jak funguje optimalizace sítě.
Postup operace
Známe velmi detailně stav duplicit, všechno máme zmapované a zdokumentované. Přichází nejkritičtější fáze. 301 redirecty necelé tisícovky subdomén a přibližně 100.000.000 URL.
Všech 1000 parametrických subdomén jsme si připravili do tabulky a rozdělili do menších logických celků – postupných vln redirectů. Pracovali jsme s několika variantami, jak by měly redirecty probíhat a jak by měly být rozfázované.
První úspěšné testy proběhly v létě 2019 a naším cílem bylo mířit k tomu, aby vše bylo hotové do konce roku. Tabulku parametrických subdomén jsme proto nakonec seřadili podle sezónních priorit a potenciálních rizik dle rozsahu dané subdomény.
První vlnu většího testu redirectů jsme provedli na subdoménách s minimálním rizikem negativního dopadu. V dalších vlnách pak následovaly sekce z oblastí elektroniky, zimního a vánočního zboží, aby byl dostatek času před začátkem hlavní sezóny pro stabilizaci redirectů, pozic ve vyhledávání a případně doladění nějakých nečekaných bugů.
V dalších čtyřech vlnách následovaly méně významné a mimosezónní sekce. Proces přípravy a plánování touto cestou zabral o něco déle, ale byl výrazně bezpečenější a efektivnější. Vynaložené práce navíc rozhodně nelitujeme.
Pooperační péče
Průběžně jsme pochopitelně museli všechno vyhodnocovat. K tomu jsme primárně používali Kibanu a Google Analytics. Analytika u subdomén ovšem není úplně jednoduchá a dost jsme s tím bojovali.
Regexátor
Abychom mohli vyhodnocovat změny efektivně, tak jsem si museli postavit v Google Sheets mini nástroj Regexator. Umožnil nám jednoduše vytvářet regulární výrazy z vložených URL. Regex jsme následně využili jako základ custom segmentu v Google Analytics.

Nástroj se dnes jmenuje URL Regexator, je rozšířený o mnoho funkcí a je dostupný pro veřejnost jako javascriptová webová utilita.
Organická vizita
Všechny změny byly velice pozitivní. Na níže uvedeném screenshotu z Google Analytics vidíte vyhodnocení redirectu téměř všech parametrických subdomén. Zobrazen je pouze Google Organic. Oranžová křivka jsou parametrické URL v kategorii, kam byl postupně přesouván traffic. Modrá křivka jsou parametrické subdomény. Vertikální červená linie naznačuje první redirecty. A horizontální červená linie slouží pro vizuální srovnání trafficu před a po.
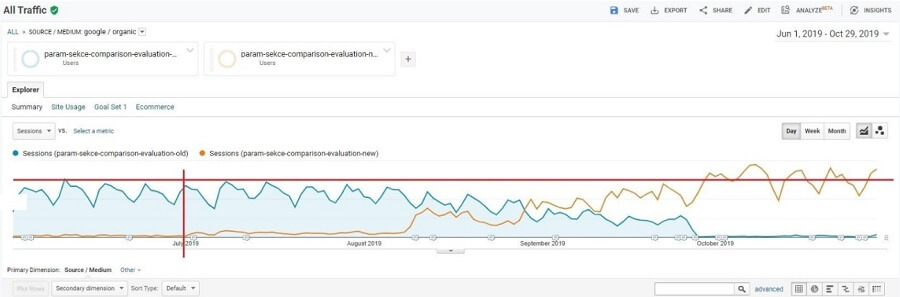
Redirecty byly sice rizikovým krokem, ale ve finále nám přinesly více traffcu. A také zvýšení konverzního poměru. Což je sekundární dopad toho, že jsme uživatele přestali držet v nepřehledném systému jednoúčelových subdomén a umožnili jim používat užitečné zkratky v kategorii, dali jim volnost pohybu a více možností výběru.
Rehabilitace
Ještě jsme tu nezmínili jednu důležitou věc. Tvorba nových parametrických sekcí byla několik let blokována, aby nedocházelo k vytváření nových subdomén. Po dokončení prací jsme se museli plynule přesunout na analýzy klíčových slov, abychom mohli začít efektivně cílit na další důležité klíčové fráze.
Pro každou kategorii jsme začali dělat rychlou analýzu. Kategorií máme kolem 2500. A každá mikro klíčovka zabrala kolem 20 minut práce. Rychle jsme pochopili, že tudy asi cesta nepovede.
Systém Junior
Část práce na mikro analýzách klíčových slov měl původně dělat juniorní SEO brigádník. Místo toho jsme se rozhodli udělat krok směrem k experimentální automatizaci pomocí SQL.
Vytvořili jsme jednoduchou poloautomatizovanou sestavu několika tabulek a SQL dotazů. Umožňuje nám to zpracovávat a dlouhodobě uchovávat velké objemy datasetů klíčových slov a rychle z nich generovat výstupní analýzy. Ukázku SQL uvádíme níže (celý script je cca 3× delší.)

V současnosti se jedná o jednoduchý prototyp a proof of concept. Do budoucna plánujeme rozvíjet plnohodnotný nástroj v Pythonu nebo Go, který bude fungovat automaticky od začátku až do konce a bude mít i uživatelské rozhraní, aby ho mohli využívat i kolegové z dalších oddělení.
Ante mortem
Web i kategorie přežily operaci bez úhony. Dál fungují a mohou růst správnějším směrem. Z dat jasně víme, že tento krok byl dobrý pro roboty vyhledávačů, ale především správný i pro uživatele, kterým se nyní web používá lépe.
Občas je potřeba se na chvíli zastavit, odříznout přítěž v podobě mrtvého masa a nádorů, abychom dali prostor pro růst něčeho smysluplného. Smrti jsme se těsně vyhnuli. A udělali jsme velký krok směrem od hrany chaosu.
Postmortem
Práce na vývoji nových parametrických sekcí se táhla několik měsíců v letech 2018–2019. Byl to hodně bolestivý a nepříjemný proces. Jednalo se o první opravdu velký zásah iniciovaný ze strany SEO. Řezali jsme do devět let zavedené struktury. Kromě toho ve stejné době probíhal velice intenzivní vývoj a postupný deployment responzivní kategorie. V jednu chvíli na stage a produkci paralelně existovalo až osm níže vypsaných verzí webu.
- Stará desktopová Heureka s parametrickými sekcemi starého typu
- Stará desktopová Heureka s parametrickými sekcemi nového typu
- Nová desktopová Heureka s parametrickými sekcemi starého typu
- Nová desktopová Heureka s parametrickými sekcemi nového typu
- Stará mobilní Heureka s parametrickými sekcemi starého typu
- Stará mobilní Heureka s parametrickými sekcemi nového typu
- Nová mobilní Heureka s parametrickými sekcemi starého typu
- Nová mobilní Heureka s parametrickými sekcemi nového typu
Nevyznáte se v tom soupisu? V pohodě. My jsme se v tom v mnoha fázích taky nevyznali. Topili jsme v potocích kódu, dat, krve a potu všech zúčastněných – vývojářů, produkťáků a webmasterů.
Poučení číslo 1: Terminologie. Na začátku projektu je nutné si definovat a vyjasnit pojmy. Zmatek v označení toho, co kdo považuje za „nové“ a „staré“, nám lámal vaz nejčastěji. Perfektně sjednocená terminologie napříč produktem, vývojem a SEO je nutnost. Bohatě stačí společná 15 minutová schůzka na začátku projektu, kde se proberou pojmy a vyjasní zadání.
Poučení číslo 2: Informační šum. Minimalizovat počet prostředníků znamená efektivnější komunikaci. Pokud si informace předává více lidí, nikdy to nemůže dopadnout na 100 %. Udělali jste změnu v zadání, našli jste nějaký problém, potřebujete se ujistit o průběhu prací? Vždy komunikujte přímo s těmi, kdo danou věc opravdu řeší.
Poučení číslo 3: Předání informací. Zadání je nutné vysvětlit produkťákovi a odsouhlasit si postup. A následně je nutné zadání kompletně předat na vývoj. Osobně nebo přes call. Ne přes prostředníka. Ne přes Slack. Nestačí to.
Poučení číslo 4: Jasná komunikace. Komunikovat jasně, nebát se a mít sebedůvěru. Management, produkt, vývoj, content, performance. Všichni mají svoje priority. Je potřeba umět prosadit ty svoje. A je potřeba je pak umět předat dál.
Poučení číslo 5: Focus. Nedělat více velkých projektů zároveň. Krásné, ale takhle to většinou bohužel nefunguje. Vždycky budou desítky priorit a vždycky se bude dělat více věcí zároveň. V Heurece nám v tomto hodně pomohlo zavedení metodiky kvartálních OKR. Pokud je situace neúnosná, tak potřebujete dalšího parťáka do týmu.
Docela vtipný seznam, že? Není tu nic, co se přímo týká precizní analýzy dat, skvělých znalostí SEO či volby správného programovacího jazyku. 301 redirecty, analýzy a vyhodnocení jsou relativně triviální a rutinní záležitosti. Všechno se motá jen a pouze kolem efektivní komunikace, chytře nastavených procesů a projekt managementu.
Sterilizace chirurgických nástrojů
Možná vás zajímá, jaké jsme používali v průběhu této práce nástroje. Uvádíme proto stručný soupis.
- Screaming Frog
- Excel
- Google Sheets
- Gephi
- Google Analytics
- Kibana
- Google Search Console
- Marketing Miner
- Collabim
- Valentina Studio
- Mozky
Závěr
Masivní změnou parametrických sekcí se nám podařilo odstranit cca 1,5 % z celkového počtu 65.000 subdomén. Přesměrovali jsme přibližně 100.000.000 URL. Což nám uvolnilo prostor pro vytvoření několika tisíc nových parametrických sekcí, se kterými můžeme pracovat dle libosti a bez jakéhokoliv rizika.
Operace trvala dlouho, ale zdařila se. S nově nabytou motivací jsme se rozhodli vyhlásit válku dalším subdoménám. Příští díl seriálu se jmenuje „Řízená SEOcida plošným vypalováním“ bude pojednávat o 60.000 brandových subdoménách. Text plánujeme vydat v průběhu roku 2020.
Seriál o SEO a subdoménách
Disclaimer
K textu přistupujte obezřetně. Tento článek a celý seriál neslouží jako návod. Texty neobsahují žádné „univerzální“ pravdy. Každý web představuje unikátní systém s různými výchozími podmínkami. Je nutný individuální přístup a perfektní znalost konkrétního webu i dané problematiky.
Článek popisuje náš web. Nijak nehodnotíme obecnou efektivitu subdomén či adresářů. Ani nedoporučujeme žádné konkrétní řešení. Opět se jedná o silně individuální záležitost, kterou ovlivňuje mnoho faktorů.
Strategie a detailní plány pro některé zde popsané aktivity vznikaly více než rok. Vše bylo mnohokrát diskutováno, průběžně testováno a validováno. Myslete na to, prosím, až budete podobné aktivity sami dělat.
Některá uvedená data mohou být nepřesná a účelově zkreslená. Konkrétní čísla, jako jsou například statistiky organické návštěvnosti, revenue, konverze a podobně, nemáme z pochopitelných důvodů v plánu vypustit ven. Klíčové informace, jako jsou počty subdomén, URL a naše postupy, jsou však uvedeny pravdivě bez přikrášlení.
Texty mohou obsahovat pokročilé koncepty a modely, které nejsou v oblasti SEO úplně standardní. Články je proto doplněny o poznámky pod čarou se zdroji, kde je vše detailně vysvětlené.
Poznámky:











 Dej nám follow
Dej nám follow
 Dej nám follow
Dej nám follow